
The Software Architecture of Palia
- Company
- Tech
- Team
- Games

Singularity6’s debut game, Palia, is a free-to-play cozy online multiplayer community simulator. A place where players can play alone or with their friends to experience a beautiful and welcoming world which can be explored and personalized.
Social interaction and a persistent shared world are key features of the game. But these elements are also some of the most challenging to implement, scale, distribute geographically, and operate at minimal operational cost and negative player impact.
Players experience the art and soul that our development team has poured into the game, but the infrastructure that makes it all possible behind the scenes is hidden from view. We are proud of what our team has accomplished with Palia, and we want to spotlight the studio’s hard work, including what players don’t experience directly. We also want to share some important lessons learned during our journey; we hope that sharing the lessons learned while developing Palia can be useful to others facing similar challenges.
Now follow us behind the scenes of our Palia development journey!
Game Engine
Building an online multiplayer title from scratch benefits from a robust and proven game engine. We made the choice to build Palia using Unreal Engine. Unreal gives us powerful tools to build with out of the box, such as a strong networking and replication library to build social features, a graphics pipeline to build a beautiful world, a powerful physics engine that can simulate complex environments, and so much more. We use Unreal Engine for our game servers as well as our client, which gives players a real-time interactive environment.
Each instance of the game server currently hosts up to 25 players, and we split up each server by what we call a map. These can be permanent fixtures, including our central hub Kilima Village, or even temporary available experiences, such as our Maji Market, which was only available for one month during our Luna New Year in-game event. When players travel between maps in Palia, the game client disconnects from one server and connects to a new one. We will share more details on how this works in our matchmaking service deep dive section.
This synergistic model is crucial for our team: we can develop most of the logic for Palia inside the engine and deploy to both clients and servers. This allows anyone on the team to test both the game and the game server in editor mode, which has been critical for our development velocity.
Spotlight: memory leakage
Unreal Engine servers are commonly used in “session-based games,” such as Fortnite: games that start and end within a certain amount of time. Memory leakage is not a big concern for session-based games because a new server is spun up for a new match and destroyed when the match ends. Any leaked memory will be cleaned before the next batch of players begin playing.
Palia is a persistent shared-world game and the lifespan of our game servers is variable depending on how players move through the game world. A single game server may remain online and serve players for an entire patch cycle which could be weeks. Memory leakage which is cleaned up regularly for a session-based game can grow and compound, and small leaks might end up consuming two or even four times the amount of Random Access Memory (RAM) proportionally affecting our operational costs.
To combat this issue, we invested in solutions to help us identify memory leaks, and we spent useful time designing nudges for players to travel between maps as to increase the likelihood that a server would empty out and be shut down.
Unexpectedly and fortunately, increasing geographical distribution helped with this problem: hosting servers near players not only helps with latency (because it reduces the distance that signals need to travel); but also with rotating empty servers because players tend to play at the same times, making it rare that somebody in that region is playing in the middle of the night and increasing the probability of servers to become empty, shut down, and cleaned.
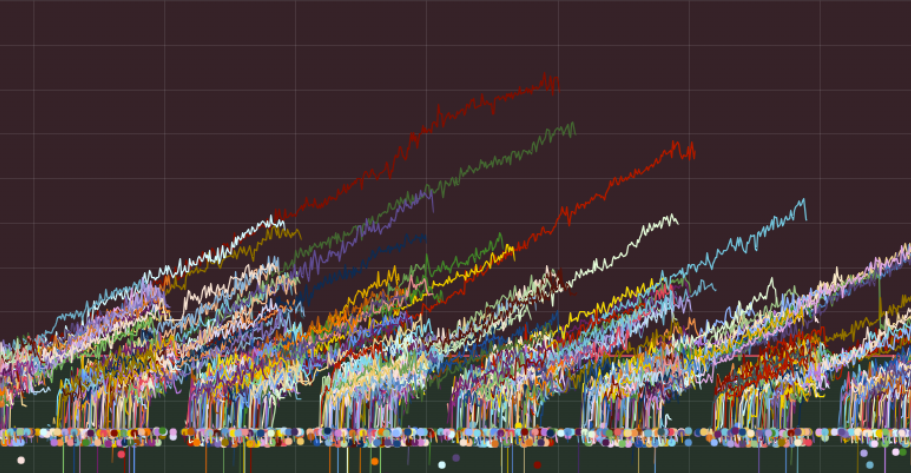
This screenshot from one of our monitoring dashboards shows the memory
usage of a portion of our game servers over a24h period in Feb 2024.
The trend of linear memory increase is clearly visible.
Services
The game client and servers talk to our services for specific actions, such as logging players into the game, loading characters, saving progress, sending chat messages to other players, making purchased outfits are stored in the player’s closet and many more.
We loosely follow a “microservice” posture, in which we prefer to host many different services specialized on one player feature.
We use HTTP as the North/South protocol (in and out of the datacenter) while we use gRPC for East/West communication (for services talking to each other inside the datacenter).
We use Rust exclusively as the programming language for our services and we try to include both integration and load testing as part of the definition of “done” for key services, including matchmaking, player presence and player state persistence which represent the largest percentage of our request load.
Our unit and integration tests are also written in Rust, but we use Locust to support and execute our load tests. Locust load tests are written in Python which is simpler to program. The ability to quickly write and modify load tests was beneficial to us and sped up adoption.
Spotlight: Rust for Microservices
Rust is a beloved programming language by many systems programmers because it provides state-of-the-art protection against common software vulnerabilities (buffer overflows and race conditions, for example) without introducing any performance penalties.
Rust is also a modern programming language. It is surrounded by a diverse and vibrant community of contributors and a wide range of libraries and tools. Documentation is excellent (especially onboarding tutorials) and the compiler is surely one of the most helpful and user-friendly.
Of course, no programming language is perfect. Rust's posture is heavily focused on correctness, which is generally beneficial, but comes with a significant upfront cost which is visible in our development velocity. Rust makes it very hard to “cut corners” and punt hardening for later. It is a very good quality when something that was supposed to be just a prototype becomes load bearing in production by sheer pressure of business needs, but it makes it hard to move quickly and with agility around shifting requirements (which is a constant in startups and game development).
The other issue was hiring and onboarding. Rust’s relative youth as a programming language makes it somewhat difficult to hire people that have production experience with the language. Although the language is very popular, few people have used Rust in a professional team setting. Most people who have Rust experience have only used it for personal projects. With this in mind, onboarding took much longer than we expected. We factored 90 days to get engineers up to speed, but it turned out to take at least 6 months for most of the team to get comfortable and confident with the language.
We are very happy with the performance, latency, scalability, robustness and security of our Rust services. But there are moments when we wonder how much opportunity cost was spent in forcing up-front solidity of every piece of this layer.
We consider it an advantage for the studio to have managed to amortize those onboarding costs and the maintenance costs of our services is indeed very low, but those thinking of following our footsteps down the Rust path, should be willing to allocate a significant effort to education and onboarding. These costs will likely reduce over time as Rust becomes more popular in production settings, but it’s unclear what that rate will be.
Several of our services are interesting and sophisticated enough to merit more attention: player state management and matchmaking.
Player State Management
We consider player state all the information that a game server needs to recreate the most recent game world experienced by the player. The architecture of our game is server-authoritative which means that game servers decide the state of the world and act as referees when game clients report inconsistent data (for example, because of time delay in transmission). We took this route because Palia is a social game so a player cheating or modifying their state could have a negative impact on the experience of other players. The risk of cheating is reduced when it's our system that ultimately controls player state.
The simplest way to persist state is to wait until a player exits a game server and have the server send this information to the database. Unfortunately, this makes state changes in that server vulnerable to the server itself crashing and losing that data (which is only kept in volatile memory for performance reasons). Instead, several times a second we check for player state changes, and if there are any, that data is immediately queued and sent to the database to be persisted.
Spotlight: data first vs. schema first
A source of contention around player state is the modeling lifecycle: who and what decides what is valid to be stored into such a state? Traditional data-modeling techniques suggest a “schema first” approach: the structure of the data (the schema) is created ahead of time and then only data that conforms to that structure can be saved into the database.
This has the advantage that the database validates the shape of the data. The disadvantage is that one has to know ahead of time the structure of the data needed… which can be challenging to coordinate across different teams.
To increase the ease with which game engineers and technical designers could work, we decided on a different model in which the structure of the data would be decided in C++ structs directly within Unreal and then marshaled and persisted in the database as a binary blob (using the Flexbuffer format). The schema is the struct declaration itself and we use Unreal’s runtime type reflection system to export the schema to our database.
The advantage of this architectural choice is that it enabled game engineers to develop features that required state persistence without the need for constant coordination. The downside is that the data is opaque to the database, which is more expensive to keep uniform and consolidated. This has required us to invest in additional tooling around the player state management system to validate, backup, modify and correct player state when it diverges from the expected structure.
Despite the additional layer of development investment needed to provide hardening on top of what the database normally provides, we believe this architecture has significantly cut down the time required to deliver new features with data persistence, such as our most recent Luna New Year event.
Matchmaking
In many competitive-style online games, matchmaking is the process of selecting people for a match. For Palia, matchmaking means matching the player with the game server that we believe will give players the best gameplay experience.
There are several dimensions that we take into consideration during matching:
- Location - how far away the game server is from where the player is currently playing (because closer server means lower latency and lower latency means a more fluid and immersive experience)
- Friends - how many of the player’s friends are currently playing on that server (because the more people they know the more meaningful their interaction will be)
- Population - how many people are playing on that server (because the more people are playing the more alive the world feels)
The matchmaking system is designed with extensibility in mind, allowing us to add more signals to the matching algorithm over time if we desire.
Another crucial feature of the matchmaking system is the ability to distinguish “join” requests and “travel” requests. A join request happens when a player starts the game and wants to join. A travel request is a match required by a player leaving one map of the game and traveling to another.
The ability to distinguish the two allows us to offer priority to “travel” requests when the system is under load and there is high contention. This is because it’s far less disruptive for players to wait a few minutes to join and then wait only a few seconds to travel between maps, than one in which the delays are spread uniformly across all matching requests.
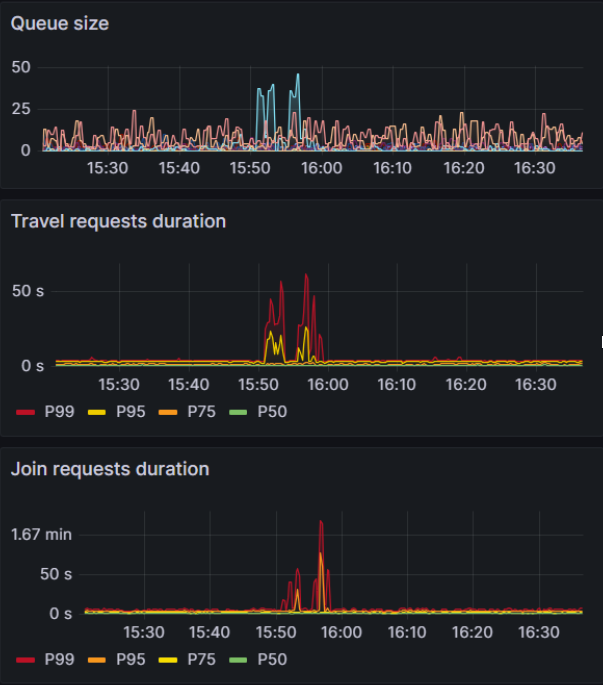
This screenshot shows a piece of the dashboard we use to monitor
queue sizes and the distribution of times it takes for a
matchmaking request (join or travel) to be satisfied.
Spotlight: game-aware internal queueing and autoscaling
Every empty server running in the cloud without a player on it is a waste of money. On the other hand, there might be players who want to play and all of the game servers have their allocated slots filled so they would benefit from an empty server to land in.
Many online games design “login queues” or similar ways to restrict the inbound flow of players and scale up or down the number of servers to meet the demand. Originally, this was our intent as well, but we realized we would benefit from a more sophisticated matchmaking design that could distinguish between joining and traveling. We also realized that the matchmaker had all the information it needed to control the size of the game server fleet.
This is how we came up with the Admiral: a component of the matchmaking system that oversees the fleet of game servers. The Admiral understands when the current fleet of game servers is insufficient to satisfy the number of players requesting a match and is able to ask the underlying cloud system (specifically Agones) to request the creation of more game server instances. Agones, on the other hand, is responsible for shutting down game servers that have been empty for some time.
The integration of autoscaling with matchmaking and the separation of concerns between the Admiral (scaling up) and Agones (scaling down) has served us very well and has managed to provide us with shock absorption to the game when things didn’t go as planned. Several times, the elasticity of these queues between maps have saved the team from having to bring down the game entirely to fix issues during misaligned deployments or unforeseen behaviors during load spikes.
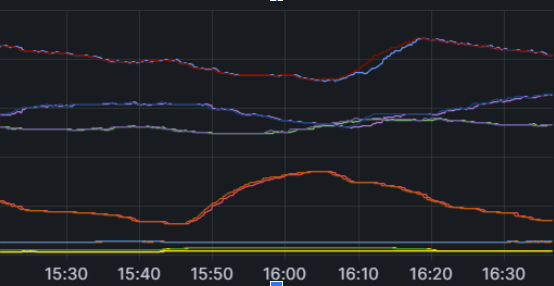
This screenshot shows the view of the game servers fleet from the Admiral.
Each line is really two lines: one for the “desired size” and another for the
“actual size”. This information is used to tell the cloud orchestrator
to spin up more game servers for a particular map type
as they are needed by players being matched to servers that don’t yet exist.
Data Management
Our architecture of loosely coupled software components wouldn’t be very useful without data flowing between them and being persisted, validated, or aggregated.
Databases
One of the most difficult elements of creating a shared perpetual world is constructing the ability for players to influence it (and one another) in a context that feels immediate and consistent. A key factor to provide a positive player experience is the choice of the database architecture.
We decided to use ScyllaDB as our main data persistence layer. ScyllaDB is a C++ rewrite of Apache Cassandra (originally created at Facebook and, in turn, heavily influenced by Google BigTable and Amazon DynamoDB), a distributed column store.
The biggest advantage of ScyllaDB for us has been its elastic scalability and its cloud native “design for failure” posture that aligned very well with ours. One significant advantage of ScyllaDB for us is the ability to attach replication strategy to a table but eventual consistency levels to a query. This gives us a lot of flexibility because in some cases we need consistency more than we need speed and we can tune that directly at the query level. This is not possible with traditional relational databases like PostgreSQL or MySQL.
This functionality is crucial, for example, when dealing with a persistent player state: we want the data to be replicated on multiple computers before we return a response to the game server. This means that both the game server and multiple database nodes have to die (at the very same time!) for that player state update to get lost. As far as we can tell, this has never happened.
We also use PostgreSQL (hosted for us by AWS) for the catalog of our outfits available for purchase in the game. We used a relational database here because we felt it was better suited for this particular job.
Asynchronous Messaging
Another important part of the data management layer is the ability of software components to message one another asynchronously.
We have two of such busses:
- The first for aggregates and collects telemetry for player behavior (which uses Apache Kafka, more on this later) and feeds our analytics and machine learning pipelines.
- Another coordinates software components (for example, the control plane between the fleet auto-scaler and the game servers). This uses EMQX as the broker and MQTT as the protocol.
Why two? Mostly because they serve different purposes, have different strengths and weaknesses, and are managed by different teams focusing on separate outcomes. There might be value in consolidating things further in the future, but for now this separation is serving us well.
Spotlight: MQTT and Apache ActiveMQ v5 (aka Artemis)
The use of MQTT as the message bus protocol for our game servers control planes was decided precisely to isolate us from lock-in of a particular broker implementation. In retrospect, this was a weak choice: MQTT is an IoT protocol and we were attracted by the fact that it was designed for devices with small power and low bandwidth. We wanted a solution that would be easy and cheap for the game servers to interact with and didn’t consume a lot of their resources.
Unfortunately, many MQTT brokers simply implemented that protocol on top of their existing native systems. We picked Apache ActiveMQ v5 (aka Artemis) because it was established and it supported v5 of the MQTT protocol (which offered features we needed) but was written and designed before clouds existed and turned out to be incompatible with our preferred “loosely coupled components expected to fail” architectural posture.
Artemis has been the source of much apprehension and tribulation. We ended up having to patch the software to fit our needs. We operated with a forked version in production just to keep it from falling over regularly (the MQTT layer and cross-regional federation layers did not work well together).
We have since migrated to EMQX which is a more modern MQTT broker, designed from the ground-up with MQTT in mind and we have not looked back.
The lesson learned here is that even established and battle-tested software might still end up performing poorly when utilized in a different context and with different operational constraints than was originally intended.
Data Pipelines
Another important principle of our software architecture is that we want to be able to observe and monitor how the system is behaving so that we can act on it effectively when behavior deviates from the norm.
We treat data differently based on whether the decision making that it supports is latency sensitive or not. In fact, we use completely different systems for low-latency decision support (seconds to minutes) vs. high-latency (days or weeks).
Spotlight: player behavior vs. system behavior
In the past, we separated data based on whether it was about player behavior or software behavior. But we quickly realized that distinction was not very helpful in practice.
For example, a purchasing event from a player is technically a player behavior and insights gathered from them influence strategic decision making with high-latency (days or weeks). But such a high-latency reaction would be detrimental to both our players and our revenue if we didn’t get notified immediately if the frequency of purchases dropped outside of the normal range of operation.
It is generally true that data generated from the behavior of players influences decision making in aggregate and with high latency while events generated by the behavior of software systems influences decisions and actions that require quick reaction times. But our ability to route data based on decision making latency needs and not on the semantics of origin has made it easier to reason about data routing decisions, especially when the two pipelines are handled by different teams with different skills, strengths, and goals.
Observability
We picked Prometheus as the time-series database powering the low-latency data pipeline and alerting. The key advantage here is the “pull” model in which it is Prometheus to “scrape” data from our software components, which makes it a lot simpler to maintain.
We also use Grafana as our visual dashboarding system querying the data stored in Prometheus along with Loki and Tempo to deal textual logs and tracing the flow of execution across several of our software components.
Lastly, we use Sloth to automate the generation of SLOs.
Analytics
The high-latency data pipeline revolves around Apache Kafka (managed for us by Confluent) which captures and routes the data as well as Apache Spark (managed for us by Databricks), which we use to aggregate and analyze the data.
We use Apache Airflow (managed for us by Astronomer) for monitoring and scheduling long-running workflows for data aggregation and analysis. Lastly, we use Tableau to power the visualization of the insights that result from our data analysis.
Cloud Infrastructure
Another development challenge is the “free-to-play” nature of our distribution strategy. This approach made it difficult to predict the amount of players that would play the game, especially around key events, such as platform launches, major updates, and in-game events.
We decided to be “cloud native” from the start because “elasticity” in supply of computation and bandwidth is a key advantage that cloud providers have over acquiring and maintaining our own server infrastructure; especially for gaming startups (for which capital is constrained) and when deploying across multiple geographical regions.
Cloud native for us didn’t simply mean: “run our programs on somebody else’s computer.” Cloud native for us meant designing a software architecture composed of small pieces that are loosely coupled and always expected to fail.
We call this “designing for failure.” Of course, we never want our systems to fail. However, we believe that resiliency in software systems comes less from preventing failure, and more from providing mitigations to such risks and the ability to restore service as quickly and automatically as possible. We want to design to reduce failure but we always expect it to happen, so when it does happen, our systems would not be surprised by it.
Key components of this strategy were using Kubernetes as our orchestration system, Linkerd as our service mesh, Traefik as our load balancer and Agones to manage our fleet of game servers. We also rely heavily on the “infrastructure as code” principle, using Kustomize to help us keep our configurations DRY and ArgoCD to power continuous deployments.
Kubecost helps us measure costs, and we recently swapped from cluster-autoscaler to Karpenter to optimize cluster elasticity and to help pick the best server instances. This change allowed us to save a non-trivial percentage of our cloud costs by automating the selection of instance types to use to run our workloads.
For provisioning infrastructure we rely on Terraform and Spacelift. We rely on Vault to store secrets without our cloud environments. We also conduct chaos testing using Litmus.
And we rely on a few different services for authentication and authorization systems, including FusionAuth for account management, Zendesk for customer support management, Stripe for payment processing, and Vivox for our in-game chat system.
Our only cloud provider is Amazon Web Services which provides us computers, storage, and bandwidth across multiple regions: United States, Germany, and Japan. We also rely on Cloudflare for geo-aware DNS and load balancing as well as DDoS protection.
Spotlight: Nomad vs. Kubernetes
We had originally chosen Nomad as our orchestration solution, mostly because it was perceived to be conceptually simpler and it was much more compatible with Windows workloads (which we thought we might need for testing purposes).
Unfortunately, Nomad had one very significant problem: the momentum of the development community around it was significantly smaller than around Kubernetes. This had two significant issues for us: a) we had to develop in-house solutions that the community around Kubernetes had already implemented; and b) it was harder to engage the team with a technology that many considered an evolutionary dead-end.
We made the difficult call to switch our cloud orchestration system by using the argument that our development velocity would significantly improve and our operational risks would be reduced. This turned out to be very much the case and it’s a decision we would happily make again.
Build Systems
There are two primary concepts used in the building of Palia and its supporting services: the build platform and the build system. Historically, game studios lumped these two together around the primary continuous integration/continuous delivery (CI/CD) component. We borrowed some plays from large-scale build and release systems beyond gaming: using a heavily distributed approach inspired by some of our team members’ experiences in other industries, such as banking.
To power the build system we use Jenkins, but take care to draw a distinction between the software, and the underlying infrastructure upon which it runs and integrates. While related, these things are best served by intentional, separate configuration management and Infrastructure as Code practices which can quickly become unwieldy and complex if attempting to do so under a monolithic design. The result is a hybrid cloud approach to the build system. We use both an on-prem data center and Amazon Web Services, and one side of the architecture can be maintained without potentially negatively impacting the other.
We also took the time to redesign the initial version of the build system (Jenkins pipelines) around Unreal Engine’s native tooling, namely, BuildGraph. Doing so required a lot of work up-front as the old method was cobbled together between Jenkins Pipelines and Python scripts, but the declarative nature of BuildGraph tooling has allowed us to increase correctness, reduce build system maintenance, and increase flexibility such that we can build almost every target platform with minimal specific changes for each. A key component of this success was integrating with AutoSDK and creating a “standard library” of sorts in Jenkins to glue it all together.
In our latest version of the build platform we are able to mostly dynamically scale the number of executors based on demand. The build system can then simply act as a “glue layer” to distribute requested tasks among the available executors as parallel pipeline runs. Further, we’ve incorporated designing for Self-Service by other teams, such that they can “pick and choose” which artifacts they want built via a single interface. We call this the “Prime Pipeline,” which presents a series of configurable parameters and then schedules the running of “Sub-Pipelines” to do the work, passing those parameters as appropriate. This means that via the same Prime Pipeline interface, one Engineer could choose to build only one Platform Client from the library of Clients available, and one Server, getting only those two artifacts; or they could select everything and end up with every Client and Server we currently offer as targets.
Spotlight: Capacity Management in a Hybrid Cloud World
A trade-off we make for this level of granularity and distribution is the initial difficulty in managing capacity. We use several build executors of different types and had to really break-down our pipelines and how each stage would be distributed to the executors both on-prem and in AWS. Then we had to measure a single run of each pipeline to get more accurate numbers to use for calculating instance sizes, costs, expected load, and timings for stage and whole pipeline execution. This cost us a lot of time up-front, and while we are glad we did it, it is yet another piece of operational overhead which must be monitored, reviewed, and adjusted in order to remain reasonably accurate. Changing something as simple as the Node Label of a particular pipeline Stage can have serious impacts to all of the metrics we measure, most notably, build times. Unfortunately, there aren't a whole lot of “drop-in” or “off-the-shelf” solutions for these types of systems, so we have had to track these things manually, and then automate as we go to attempt to reduce the operational burden.
Furthermore, managing two different sets of infrastructure is not for the faint of heart, or those unfamiliar with Hybrid Cloud management. While the patterns may be very similar, the implementation proved to be a lot more work than we anticipated.
For example, AWS and other cloud service providers make APIs available to interact on a very granular level with their exposed components. On the other end of the spectrum, even the most mature on-prem infrastructure providers rely on their own custom tooling for managing hardware components. This is why projects such as Ansible are in such heavy use in the IT industry, and S6 is no exception here as we prioritize the use of open source tools where possible to ease cognitive load and keep costs low.
The challenge that made this most difficult was the disparity in experience using this approach on our team members’ time. Some of us come from more of a Platforming background, others from a Tooling background, and still others from primarily a Jenkins Pipeline writing background. This is great for general cross-functionality within the team, but requires careful planning to execute well even among the highest-performing teams.
Version Control
We use two different version control systems to manage the development lifecycle of our code: Perforce for the game code, and git (hosted in Bitbucket) for everything else.
Using different version control systems is clearly suboptimal and not a decision we took lightly: git is generally preferred by backend engineers and is far better supported by modern development environments.
Unfortunately, Perforce is very well integrated in Unreal Engine because that’s what Epic Games uses (the makers of Unreal Engine). Also, git isn’t really designed to work with very large binary files, and a lot of our in-game assets and original sources are giant binary files. Perforce works well in these situations.
Early on, we tried using git-lfs (large file storage), which is supposed to help with this problem but we gave up when we realized how much effort it would be to retrofit all of the Epic development tools (UnrealGameSync, for example) to work with git.
We sincerely wish we had a single consolidated version control system and code review workflow, but it is not a trivial exercise.
Spotlight: Consolidated Repos
One of the issues we faced with git was that it was too easy and convenient to create new repositories, causing a proliferation of them. The biggest issue we faced was the inability to make changes that cross-cut different services at once. This created a lot of production overhead and reduced our ability to consolidate the behavior of services.
We considered switching to a full “monorepo” but many of us were unfamiliar with it and feared additional complexity and overhead that we had no additional development capacity to support.
The compromise we reached was a handful of consolidated repos in which many individual git repositories were merged into a single repository and then archived. All the microservices ended up in this single repository, but they could be developed, built, tested and deployed in isolation. This made it much easier to modify code across services (such as version dependencies) as well as simplifying the creation of libraries. This approach facilitated an incremental externalization of common functionality into modules that could be more easily reused across services, reducing copy/paste code duplication and reducing our maintenance costs.
SaaS-y Open Source
One common theme you might have noticed in our architecture is that we prefer to depend on software that is open source and that we could host ourselves if we wanted/needed to. We also prefer to rely on a SaaS vendor that provides and manages this software for us instead of running it ourselves.
This offers us several advantages:
- We are not locked into a particular cloud or vendor provider (as we could run the system ourselves if we needed to).
- We can provision systems more quickly (our people don’t need to learn the intricacies of configuring them).
- Leverage vendor expertise to fix issues and/or edge cases when we encounter them.
- Keeps the vendor prices under control under our threat of shutting down our vendor contract and hosting the system ourselves.
We deviated from this posture only rarely and when there was no open source alternative that made sense for our business needs. However, we do believe this paradigm worked well for us and provides a way to fund and support further development of these open source projects. This, in turn, lowers our future risks by helping make the development of these open projects more sustainable (as these hosting vendors often employ contributors to the open source projects and continue to fund their contributions for mutually symbiotic benefit).
Conclusions
It’s rare to get access to the source code that makes up video games, so it’s rare to have the opportunity to learn directly from it. Even rarer is a view into the decisions and tradeoffs, the lessons learned, the paths not taken and those taken but with later regret.
We hope that this deep-dive on the challenges and successes of creating Palia’s software architecture provides some insight and inspiration for others facing similar challenges.
If you have any questions about Palia’s software architecture and development, or simply if you want to start a conversation feel free to reach out to us at hello@singularity6.com.
Special Thanks
The list of people that contributed to this architecture is very long (see the Palia credits for the full list) and we wouldn’t do it justice to replicate it here. Here, we thank the people that helped us contributing to our editorial: Stefano Mazzocchi, Dan Ristic, Kyle Allan, Anthony Leung, Adam Passey, Brian Tomlinson, Emily Price, Jordan Orelli, Michael Chance, Javi Carlos.